Table of Contents
Creating and Modifying Record Sets in MarcEdit
Marc Record Sets will need to be edited in MarcEdit in 3 different instances (listed in order from easiest to hardest):
- Vendor Records - The vendor will provide a set of records that need to be modified
- Copy Records - Records that are created by copying existing records found in the MarcEdit Z39.50 module, or other sources like public library websites (records can be copied on an individual basis or group basis using the Batch Method - this will be looked at in Appendix A)
- New Records - Records that are created from scratch (this is a last case scenario if existing records can not be found to copy)
Some Record Sets will be a combination of Vendor Records and/or Copy Records and/or New Records. In each case, the Record Sets will end up being relatively similar - getting there will be slightly different.
After a Record Set has been cleaned up/modified/created, it will need to be converted to .xml and ingested into the NNELS website through Drupal.
Downloads
| Current MarcEdit version to install | Download MarcEdit |
| Text file with some easy to copy Marc fields | marc_fields.txt |
| Excel spreadsheet with current Genre Headings | nnels_genre_terms_20240401.xlsx |
Important Websites
| NNELS - Login → Shortcuts → Summary/Subjects Editor | NNELS |
| WorldCat - Search for Subject Headings | WorldCat |
| searchFAST - Verify and create Subject Headings | searchFAST |
Getting Started
- Set up the Z39.50 module in MarcEdit using the OCLC credentials provided to you
Vendor Records
If the Record Set is not in .mrk format, it will need to be converted in MarcEdit:
- If the Record Set is in .mrk format, just open in MarcEditor and modify from there
- If the Record Set is in .mrc format, open MARC Tools and select MarcBreaker from the dropdown menu. Open the Record Set and choose a location to Save As. Default Character Encoding should be MARC8, and both of the Translate boxes should be unticked. This will create a .mrk file, which can then be opened in MarcEditor and modified.
- If the Record Set is in .xml format, open MARC Tools and select MARC21XML⇒MARC21 from the dropdown menu. Open the Record Set and choose a location to Save As. Default Character Encoding should be MARC8, and both of the Translate boxes should be unticked. This will create a .mrc file - use the above method to convert to from .mrc to .mrk.
Copy Records and New Records
These records will be created in an empty .mrk file, so just open MarcEditor and begin there. The exception is if Copy Records are made using the Batch Method described in Appendix A, in which case a .mrk file will be created in the process.
Important Marc Fields within a Record
These fields are for the most part mandatory, or at least significant in certain ways. When copying records from Z39.50, try to find records that match the format (ie: audiobook item → audiobook record), although it's not entirely necessary. Also, generally (although not always) choose the records that are more fulsome (ie: they have more information).
When Record Sets are ingested into the NNELS website through Drupal, the .xml file will be parsed and each Marc field will have its contents uploaded in Drupal. For example, the parser will know that the 520 field is a summary of the book/material and that the 245 field contains the title of the work. Some fields are not parsed, and so are less important to the process (we don't necessarily remove those fields, as we still want to maintain good Marc records).
These aren't full breakdowns of each field - basic knowledge of cataloguing is assumed. For more information, Google marc field xxx (where xxx is the field number, eg. 245), and the first link should be to a Library of Congress breakdown of that field and its technical aspects (description, indicators, subfields, etc.).
Include end of field punctuation, and make sure subfields are formatted properly with spaces and/or punctuation as necessary. Catalogue in English, although the 520 (summary) field can be in the language of the item.
LDR
Each record needs an LDR. These are partially computer generated. They will be included in Vendor Records and in Copied Records, for New Records the LDR can be copy and pasted from the Marc Field text file.
001, 003 - Control Numbers
These will generally be in Vendor and Copied Records, but are not necessary so can be omitted in New Records.
005 - Time Stamp
This is a computer generated time stamp that records the last time the record was modified.
006 - Bibliographic Data (Parsed)
This field contains various pieces of information about the nature of the record (intended audience, form, format). You may need to modify certain components based on the content.
Example: =006 m\\\\eo\\d\\\\\\0\
- m indicates a computer file and does not change for our purposes
- e indicates adult audience - other options are: j = juvenile, d = young adult
- o indicates online material and does not change for our purposes
- 0 indicates nonfiction - other options are: 1 = fiction, d = dramas (plays), j = short stories, p = poetry
008 - General Information
This field contains the information in the 006 field and more. Drupal will take all the info from the 006 field, although this field contains 3 characters indicating the language. Vendor and Copied Records will have this field, but it is not necessary to create it for New Records.
020 - Identifier
This is usually the ISBN. 13 digit ISBNs start with 978, which makes them easy to spot. 10 digit ISBNs are rare now. This is a good place to grab the ISBN to search with in Z39.50.
028 - NNELS Identifier
This field contains an identifier that will be used for NNELS when doing batch uploads. This field should only be used when directed to do so. It will usually be one of the ISBNs.
100 - Author (Parsed)
Author's name in the form Last, First.
245 - Title (Parsed)
We take an AARC2R approach - Capitalize the first word and leave the rest in lower case, except for proper nouns (articles like The and A stay at the front of the title). Followed by the subfield /$c author's name (First Last).
Example: =245 14$aThe devil in the white city :$bmurder, magic, and madness at the fair that changed America /$cErik Larson.
260, 264 - Publishing Information (Parsed)
Use either 260 or 264 (not both). Newer material will tend to use the 264 field (which is RDA format). When the publisher's location is not known, use [S.l.]. When the publisher is unknown, use [publisher not identified]. For an unknown year, use either [year?] (ie: [2024?]) or [date of publication not identified].
3XX - Characteristics (306 Parsed)
These fields indicate the content type. Make sure the content types match - for example, you may use a Copied Record for a print book to create a record for an audiobook, in which case you will need to change the 3XX fields from print to audio (copy and paste-able 3XX fields are in the Marc Field Text File).
The 306 field is for the length of an audiobook. It needs to be in the form: hhmmss.
Example: =306 \\$a132642
This indicates 13 hours, 26 minutes, 42 seconds.
511 - Narrator (Parsed)
This is only used for audiobooks. Drupal takes the field as is, so input here in the form First Name Last Name, eg: John Doe. If you can't figure out who the narrator is, leave it blank and it can be fixed later in Drupal. Some Vendor and Copied Records will say "Narrated by " or "Read by: ", just delete these introductory statements.
If the author is the narrator, then write Read by the author.
520 - Summary (Parsed)
This can come from Vendor Records or Copied Records. If it is not present or needs to be recopied, Amazon, Goodreads, or other similar sites are good places to find this information. Some records will be in a form like this:
"Start of summary…End of summary" -- Provided by Publisher.
Or the source at the end may be different, eg: "…" -- From book jacket
Drupal parses this as is, so remove the quotation marks and the source attribution at the end.
650 - Subject Headings (Parsed)
This is an important field that can be difficult at times. There will usually be multiple 650 field entries. We want at least one. Appendix B is a batch method for copying large amounts of 650 fields at once through Z39.50.
Important note: Drupal only parses the 650 field, which is for Topical subject headings. You will come across other 6XX fields like 600 and 651 fields (People and Places). If you want these fields parsed in Drupal, you will need to change the field to 650 (it is generally safe to ignore the 648 field).
We use FAST Subject Headings (and remove the rest). They are essentially simplified Library of Congress (LoC) Subject Headings. Over time working with them, they will become easier to recognize and get a feel for.
LoC subject terms will be in the form: =650 \0$aSubject term.
FAST subject terms will be in the form: =650 \7$aSubject term.$2fast
The 0 indicator specifically identifies Library of Congress, and the 7 means the term is from a taxonomy identified after the $2.
FAST terms can also be written in the form: =650 \4$aSubject term.
The 4 indicates that the taxonomy is unidentified. This is quicker and easier to do if FAST terms are not already included in the record with the \7…$2fast format.
In the case of multi-term headings, this is where FAST is simplified.
An LoC term may look like this:
=650 \0$aRefugees$zCambodia.
FAST would handle it this way:
=650 \4$aRefugees.
=651 \4$aCambodia.
(and we would change the 651 to 650 to have Drupal parse it)
There are also instances where FAST can have multiple terms as well.
LoC term:
=650 \0$aWomen$xSocial conditions.
FAST term:
=650 \4$aWomen--Social conditions.
or
=650 \7$aWomen--Social conditions.$2fast
The subfield indicator separating the terms is replaced by 2 dashes (--). This is generally rare as most FAST headings are just a single term (as in the Cambodia example above, so you can't just do this all the time), but you will see certain terms again and again (for example, Murder--Investigation is common for mystery novels). Some Vendor and Copied Records will use subfields for FAST headings, like this:
=650 \7$aWomen$xSocial conditions.$2fast
This should be changed to:
=650 \7$aWomen--Social conditions.$2fast
When Drupal parses subject terms, it splits terms based on the subfield indicators, so if there is an $x in the subject term, the Drupal record will actually show 2 separate terms (Women, Social conditions instead of Women--Social conditions).
You can check searchFAST to verify how certain terms are handled. Over time you will learn to spot which terms are likely to use the 2 dash (--) format, but searchFAST is always a good resource for this.
Also be aware that some FAST syntaxes are different than LoC. For example, place names.
LoC: =650 \0$aGeorgia (Atla.)
FAST: =650 \4$aAtlanta--Georgia.
LoC is City first with State/Province/Country in parentheses. FAST is State/Province/Country--City. So, take care when manually converting LoC subject terms to FAST. There are also other differences, for example when dealing with people's names and their birth and death dates, and when dealing with named events (for example the Vietnam War). Again, use searchFAST to get the syntax, and then you will know going forward.
The majority of FAST terms can simply be derived from LoC terms by just taking the first part of the LoC subject term. This is most apparent when it comes to fiction.
LoC adds the term $vFiction at the end of subject terms for works of fiction. For example:
=650 \0$aMissing persons$vFiction.
The FAST term would just be:
=650 \4$aMissing persons. or =650 \7$aMissing persons.$2fast
Where to find FAST subject terms
OCLC Classify was the best place to get these terms, however it has shut down. These are generally the easiest alternatives, however if I can find something that works better I will incorporate it.
1. Z39.50. The best way to search for records in Z39.50 is by using the ISBN. This will generally return multiple records for the same item. Check each record until you find one with FAST subject headings. If the records for a particular ISBN don't have FAST subject headings, try different ISBNs (ie: Paperback vs. Hard cover vs. Large print vs. Audiobook vs. etc.). Failing that, search via title and author. Searching via title often yields pages of irrelevant records. If you must use a title search, use the AND operator and second search box to search for author Name.
Note that sometimes these Copied Records will not come with the 650 end of field punctuation (which is a . after the subject term/before the $2). Add that in.
2. WorldCat.org. This OCLC website allows you to search by title and/or author. It will return separate entries for each form of the item (ie: print, audiobook, ebook, etc.). Generally the print entries are the best to use.
After searching, click on the result and in the result page click on "Show more information" to get a variety of information, including subject headings (listed as "Subjects") - the first few subject headings will show on-screen. Click "Show more" to see all of them.
Subject headings will be a mix of LoC, FAST, French, BISAC, and more. FAST will become recognizable with experience. Here is an annotated screenshot of the subject headings for Gone Girl (Gillian Flynn):

FAST subject headings are marked with a Green Star. Notice that LoC terms are similar - in this case they just have the term Fiction at the end.
The terms that WorldCat provides do not have subfields or double dashes (--), however when there is a capitalized word (ie: "Fiction" in the LoC examples) that usually indicates a break in the subject heading.
Note: Wives Crimes against. This is a FAST term and by noticing the capitalization of Crimes, we can tell that the form should be "Wives--Crimes against. That will need to be changed when copied into a 650 field. Moving forward, "&&–&&Crimes against" is now recognizable as a secondary FAST term that can be spotted in the future.
You may also see terms that identify the genre of the item. This is what the 655 field is for, and so can be omitted in the 650 field. In the past, before LoC created a genre taxonomy, genre terms were put in the 650 field, but that is an outdated method. BISAC terms are also genre identifying so can be left out. However, these terms are a good guide as to what the genre is, and so can be helpful in creating the 655 fields.
For example you may omit this term from the 650 field:
=650 \0$aDetective and mystery fiction.
There are also deprecated LoC terms to keep an eye out for - some of the old Genre terms for fiction ended in "stories" but the new ones end in "fiction":
=650 \0$aDetective and mystery stories.
=650 \0$aRomance stories.
=650 \0$aLove stories.
These can be removed as well.
655 - Genre Headings (Parsed)
This is a mandatory field. A minimum of one is required, although most often there will be multiple. See the Excel sheet linked above for a list of Genre Terms used by NNELS.
Over time, this list will become second nature. But in the meantime it is worth using it for reference. The list is broken into Fiction, Non-fiction, and Others (terms identify things like Form, Audience, or special interest). Do not use fiction terms for non-fiction items and vice-versa. The Other terms can be applied to both (Poetry and Drama notwithstanding).
Juvenile fiction - for Juvenile fiction only use the Genre term Juvenile Fiction - do not include other fictional terms (still include general terms like Canadian fiction or Picture books, etc., but do not include things like Fantasy fiction or Detective and mystery fiction) - this is because we do not have a way to filter for audience on the website, so we do not want patrons to sort for mystery novels and get a bunch of children's books. For nonfiction, do a regular genre treatment.
Young adult fiction - treat the same as adult fiction (full genre treatment).
Canadian terms are used for items by a Canadian auther or are about Canada; Indigenous materials follows the same principle.
Picture books are used only for children's literature, usually for the standard 32 page juvenile fictional picture books, but sometimes juvenile non-fiction as well - the picture book is more of a format than just anything with pictures.
Illustrated material can be for adult or juvenile non-fiction - it can be a photography book, or an art book with paintings or drawings, or a technical book with diagrams.
Biographies and autobiographies will usually have another genre term related to the subject of the biography (ie: Music if the biography is about a musician).
Do not use both Canadian drama and Drama - just one term. Same with Poetry.
Genre Headings can be tricky. Sometimes they are a best guess. Read the 520 Summary field and use the 650 Subject Headings to make a determination. Amazon and Goodreads, as well as the publisher's website are good sources to determine the Genre(s) and intended audience (be aware that when looking to Subject Headings for guidance, LoC does not distinguish between Juvenile and Young Adult - so LoC 650 Subject Headings can say Juvenile fiction even though it should be Young adult fiction). If you can not figure out the genre for fiction, use "General fiction".
Use only Genre Headings that are in the Excel sheet. Anything that is not in that sheet (or is misspelled) will not appear in Drupal after it is uploaded. It is a good idea to keep a edit a record in Drupal, click on Genre, and keep it open - when you type start typing in the Genre, it will provide a dropdown selection menu. I will copy and paste from there sometimes when I forget certain terms.

700 - Added Entry (Parsed)
This is similar to the 100 field. There can only be one 100 field, so for example if there are multiple authors, the rest will go here; or if there is an illustrator for a graphic work. This field is less important than the 100 field.
The Rest
If you are copying records from Z39.50 there can be some junk fields at the end. Some examples include: 856, 938, 029, 994, 948. They can be lopped off. Although try to keep sets of Vendor Records intact if they include these fields.
Creating New Records
If there is a need to create a New Record from scratch, there is a template in the Marc Fields text file that can be copied into MarcEditor and modified. It includes just the necessities. The 3XX fields may need to be changed, and the 511 field may need to be deleted if the item is not an audiobook. The 028 and 700 fields can be deleted if unneeded. The 006 field will need to be modified depending on the material. I have included the proper spacing, subfield punctuation and end of field punctuation.
Final Step - Converting .mrk Files to .xml for Upload to Drupal
- From the main screen of MarcEdit click on Marc Tools
- Select the MarcMaker Operation
- Open the .mrk file
- Save as a .mrc file (you can use the same filename, but with the different file extension)
- Default Character Encoding should be MARC8
- Check Translate to UTF8
- Click Execute - this will generate a .mrc file
- Select the MARC21⇒MARC21XML Operation
- Open the .mrc file
- Save as a .xml file (you can use the same filename, but with the different file extension)
- Default Character Encoding should be changed to UTF8
- Uncheck Translate to UTF8
- Click Execute - this will generate the .xml file.
Appendix A - Batch Method for Copying Records
If there a list of ISBNs is provided, this method can be used to acquire records for all of them at once using Z39.50. This method works best when ISBNs are provided in an easy to copy way (for example in an Excel sheet). Generally this method is best for larger lists of items - it is probably not worth doing for, say, 10 or less.
The ISBNs need to be copied into a .txt file - one ISBN per line, with no header at the top.
Open Z39.50 and make sure ISBN is selected from the dropdown menu, check Batch Search, click the folder icon to navigate to the .txt file, and lastly click Search to create the .mrk file that the results will be saved in.

Z39.50 will download all records with those ISBNs into the .mrk file. Each item will probably have a few records downloaded for it, so the next step is to open that .mrk file and determine which Copied Record is best and delete the rest. Then those remaining records can be modified as normal.
Appendix B - Batch Method for Copying 650 fields
This method is useful for large sets of Vendor Records. Often vendor sets will come with BISAC and/or Overdrive Subject Headings. It can be cumbersome and time consuming to replace those with FAST headings. Like in Appendix A, this method is only worth doing for larger record sets. This method will involve extracting the ISBNs from a record set, searching for Subject Headings in Z39.50, deleting all non-FAST headings, and merging the FAST headings with the original record set.
Create a List of ISBNs
- Make sure the record set you want to add the Subject Headings to is in .mrc or .mrk format (some record sets come in .xml format and need to converted using Marc Tools module
- Select Tools from the toolbar in
MarcEdit → Export → Export Tab Delimited Records
- Use the default delimiter options, click on the folder icons to select the .mrc/.mrk file to open and the .txt file to save the ISBNs in (this method requires that the Vendor Records have ISBNs included in them), and click Next
- Check Normalize field data, select 020 from the Field dropdown menu, and put "a" in Subfield (without the quotation marks), then click Add Field, and then click Export
- Open the .txt file in Excel
- The Import Wizard should open -use the default settings (Fixed width) and click next
- Step 2 in the Wizard allows you to move the line breaks by moving the arrows - move them to either side of the ISBN and click Finish
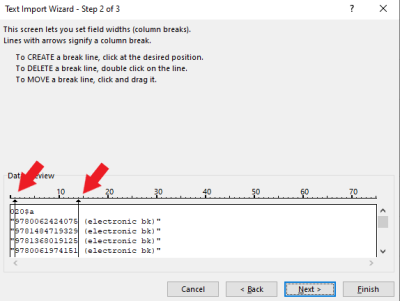
- Delete any rows and columns that don't have ISBNs - You should only have one column with 1 ISBN per cell
- The ISBNs will appear in scientific notation - this needs to be changed by selecting the column of ISBNs
- Right click on the cells and select Format Cells
- Click on Custom, select 0, and click OK
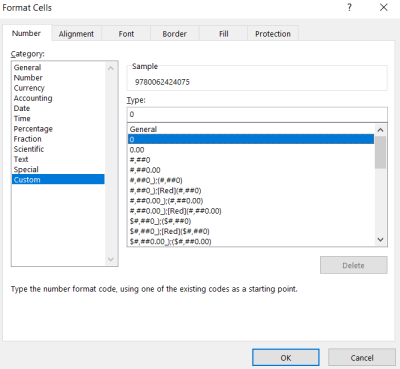
- Copy the ISBNs into a text file - one ISBN per line



Batch Search for Records
Open Z39.50 and make sure ISBN is selected from the dropdown menu, check Batch Search, click the folder icon to navigate to the .txt file, and lastly click Search to create the .mrk file that the results will be saved in.
Z39.50 will download all records with those ISBNs into the .mrk file.
Formatting the Subject Headings
- Open the created .mrk file in MarcEditor
- Press CTRL+R (or on the Toolbar click Edit and then Replace)
- In Find enter 600 and in Replace enter 650
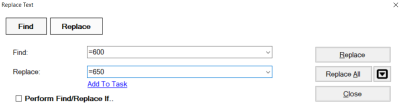
- Repeat, except in Find enter 651 and in Replace enter 650 (these 2 steps will make sure that Drupal can parse Name Subject Headings and Place Subject Headings - because if you remember, Drupal only parses the 650 Field for Subject Headings)
- On the Toolbar click
Tools → Edit Field Data - In Field enter 650, in Find enter $x, in Replace enter --
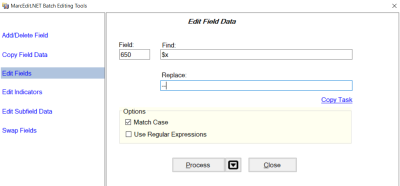
- Repeat with any other subfields that need to be changed to dashes
- On the Toolbar click
Tools → Edit Field Data - In Field enter 650, in Find enter $2fast, in Replace enter .$2fast
- Now in Edit Field Data, in Field enter 650, in Find enter ..$2fast, in Replace enter .$2fast


Removing Non-FAST Terms
- In the same .mrk file on the Toolbar click
Tools → Add/Delete Field - In Field enter 650, in Field Data enter $2fast, check Remove if field data does not match, then click Delete Field
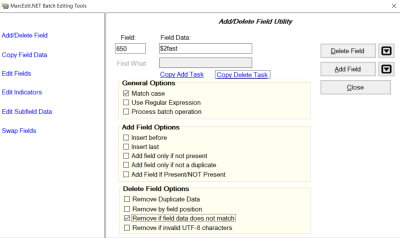
- A quick check should show all non-FAST Subject Headings have been deleted
- Save as a .mrk file and close MarcEditor

Merging Subject Headings with Original .mrk File
- From the main MarcEdit screen select Merge Records (if it is not there type Merge in the top-right search bar)
- The Source File is the original Vendor Set (should be in .mrk format)
- The Merge File is the .mrk file that we just created
- The Save File is the file that will be created by merging the Source and Merge Files
- Change the Record Identifier to 020$a and click Next
- In the Left Box select 650 then click the top Green Arrow (→), then click Next
- The final merged .mrk file will be created
Final Cleanup
Have a look through the final .mrk file to check that the Subject Headings were added properly. There may be some subfields that still need to be changed to dashes (&&–&&). There may also be some $d subfields that need to be modified as well (for Names and/or Named Events).
